In this article, we present a compilation of effective strategies and methods to optimize application performance by minimizing API calls. By reducing the volume of API requests, you can effectively manage peaks in API usage and decrease associated costs.
Drawing from our extensive experience analyzing the inner workings of numerous applications, we have identified common pitfalls and missteps made by developers during implementation. This article is a result of our observations, providing valuable insights and best practices for achieving application optimization.
This article is a work in progress. We will be expanding it with additional ideas and best practices.
Avoid excessive Logging API
Logging API usage can become a significant portion of the total API requests made by your application. The API calls are generated by using:
the Logging API in your app
the Logging API Codeless blocks.
the console.log function in your Cloud Code JS business logic
the print Codeless block in your Cloud Code Codeless business logic
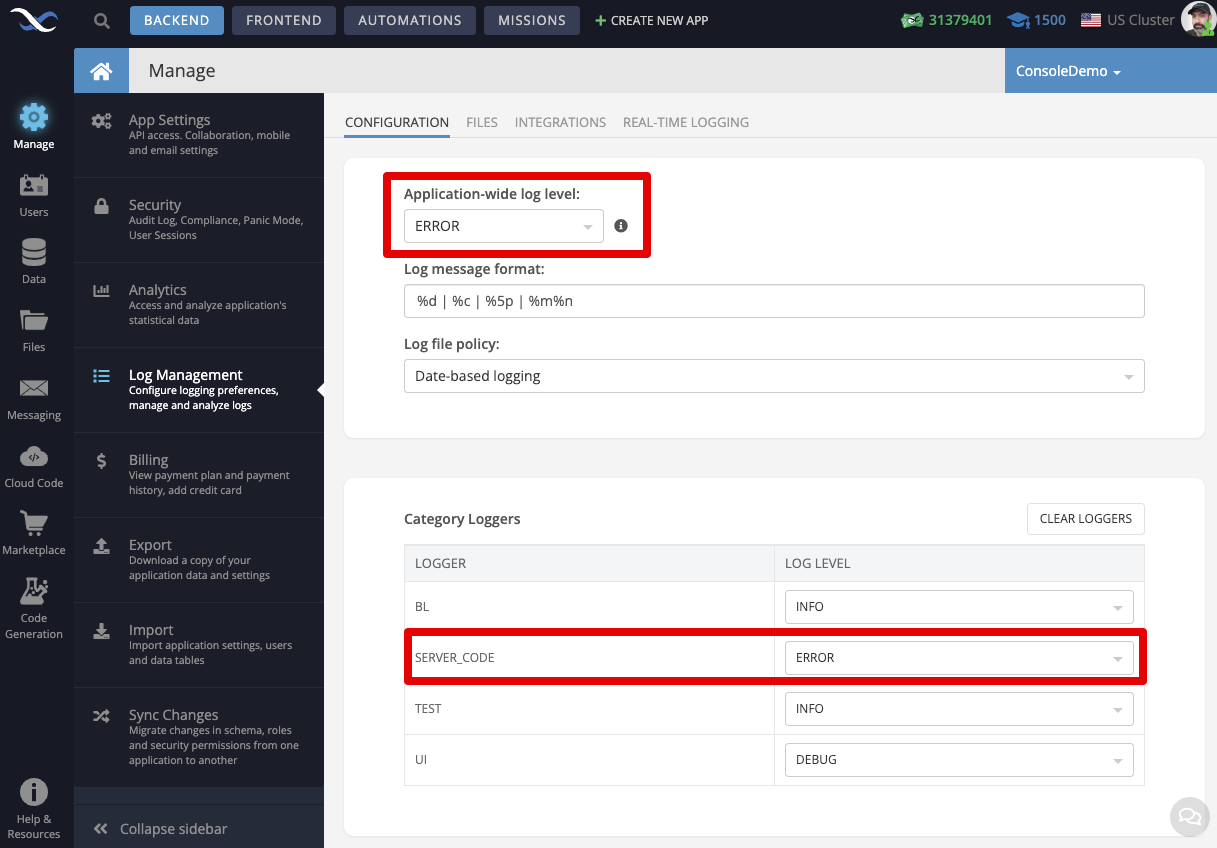
It is recommended to comment out or remove any logging requests of a debugging nature from your applications. Keep only what’s absolutely necessary. Additionally, use the Log Management screen to set both application-wide and specific loggers (such as SERVER_CODE for instance) filters to prevent log messages for up to the selected log level from getting logged and thus counted as an API call. Read the documentation about Log Levels and App-wide logging.
Load data once and cache it
Quite often we see app logic that retrieves the same data from the same data table using the same where clause queries in multiple places of the same UI Builder page or across different pages. In most cases, these repetitive data retrieval operations are not needed at all. Simple caching of the data set in the App Data data model (or Local Storage) would not only save multiple (redundant) API calls but yield better performance of the app.
For the applications built with UI Builder, as well as apps that work with file-based content (images, files retrieved from the Backendless File storage, etc.), consider adding CDN integration as it will significantly reduce the number of File Download API requests and improve load and render speed.
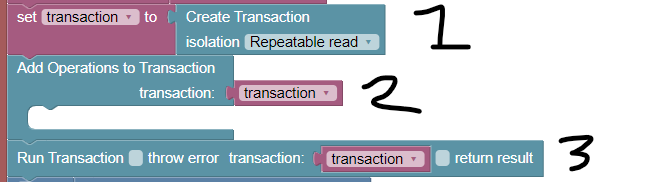
Group multiple DB operations into transactions
Transactions API provides multiple benefits over running individual database operations. Suppose your logic/code performs the following:
1. Save object A
2. Save object B
3. Retrieve a collection of objects from Table C
4. Create a relation between A and B and the collection from C
These operations can be grouped into a single transaction. Not only it will consume one API call instead of four, but the system will also ensure transactional consistency where if any one of the operations fails, the entire transaction will be rolled back.
Use the DeepSave API whenever you can
While the Transaction API may be too complex to use, the DeepSave API provides a simple and very powerful way to create/update the entire object hierarchies with a single API call. For example, consider the following individual database API calls:
1. Create object A
2. Update object B
3. Create object C
4. Create object D
5. Create a relationship between A and B
6. Create a relationship between B and C
7. Create a relationship between B and D
These seven API calls can be grouped into a single DeepSave API request by saving the hierarchy of object A with all the related objects. The object “tree” to save would look as shown below:
A
└-B
├-C
└-D
Use Bulk methods instead of individual create/update/delete requests
Whenever you run into a situation where your logic/code loops through a collection/list of objects and saves/updates/deletes them individually, you should change it to use the BulkCreate, BulkUpdate or the BulkDelete operations/API. These APIs can save/update/delete multiple objects with a single API request. Huge savings with the API usage and great performance optimization.
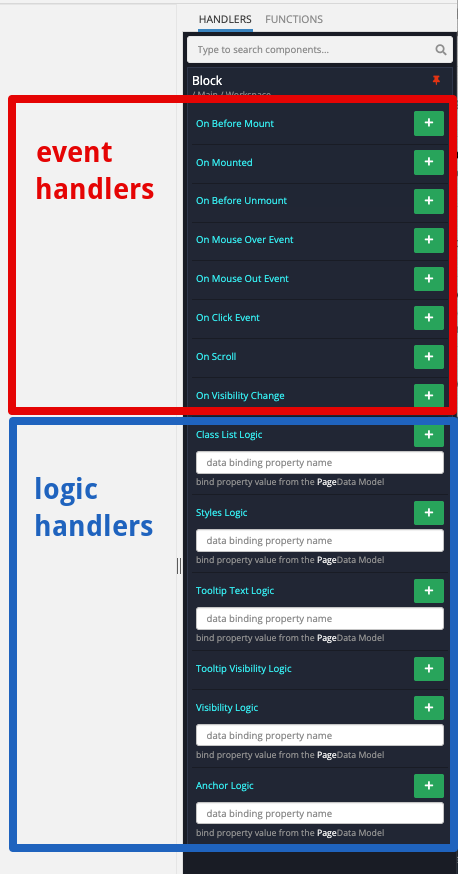
Do not use any of the API blocks in the Logic Handlers in UI Builder
First of all, what are the “Logic Handlers”? Please see below for an example:
Logic Handlers respond to changes in the data model, while Event Handlers respond to actions by the user as well as component life cycle events (such as On Before Mount, On Mounted, On Before Unmount. The Logic Handlers run on each re-render. If you have any API Blocks (i.e. most blocks in the BACKENDLESS section of the codeless blocks library), it will generate a lot of API Calls. This is because the logic will run on every re-render and those happen quite often. As a result, avoid using any API blocks in Logic Handlers. Instead, load data or use any other APIs in the Event Handlers and rely on Data Models to represent the data in the UI. For example, a good place to use the APIs would be in the OnBeforePageEnter or the OnBeforeMount event handlers.
@mark-piller Are API calls from within Cloud Code also handled/counted the same way? Or will putting multiple other API calls behind a single custom API be beneficial in any way in this regard?
API calls from within Cloud Code are counted the same way as from anywhere else. An API call is an API call, the backend resources are used to execute it.
Regarding Item #2 in your list above Mark - load data once and cache it - are there any good examples or videos on doing this?
I understand the concept, but since I have never done this before:
What is a good implementation of retrieving a simple data structure from the database, and then retrieving this from e.g. Local Storage, but at the same time making sure that if there ARE changes in the database, fetch it all over again?
The data you store in there can be anything - primitive values, objects, lists.
The traditional approach would go like this:
App starts
Try loading data from local storage
If (2) is not empty, go to 4. Otherwise, fetch data from the server. Once you have the data, cache it. Go to 6.
Check the timestamp of the most recent record in the cached collection. Fetch data from the server that is newer than the timestamp. This will get you the delta between what you have in the cache and what’s in the database.
Merge the delta with what you have in the cache. Here there may be different strategies, For example, you may choose to retire some older objects if needed.
@mark-piller When you need to load data for a given page, is it benefitial to use the transaction API to do this and group the calls together? These are unrelated data that needs to be loaded from different tables (in my use case at least).
@mark-piller Can you clarify something about transactions for me (and everyone else)? In your example, you list have four operations that could be grouped into a single transaction. You mentioned this would consume 1 API instead of 4.
However, doesn’t it require two additional API calls? One to create the transaction and a second to run the transaction for a total of three.
I just want to confirm it only makes sense to use transactions if it will replace three or more API calls, assuming there is no need for transaction management.
Does logging these errors count toward billable API calls? It seems reasonable I should have a way to log and have accountability for when there are errors, but at the same time, these could massively increase the API count if part of Backendless is down and I have heavy usage.
If these count toward API billing, what log level doesn’t log these?
These should be excluded from billing (if they count) since I have no control over them, and no one wants to see these errors in the logs (Backendless or customers).
Does logging these errors count toward billable API calls?
Yes such internal server errors also count towards the billing when they are logged by client SDKs via API.
If these count toward API billing, what log level doesn’t log these?
They will be always logged when logging in enabled. You cant turn them off.
These should be excluded from billing (if they count) since I have no control over them, and no one wants to see these errors in the logs (Backendless or customers)
I will discuss this moment with the team and we will try to figure out how we can improve/change this situation.
To exclude such errors from app log you should turn off “SERVER_CODE” logger explicitly. With such approach internal server errors will not be logged. For cases when you need to log errors in your server code you should use your custom logger with such approach.
Thanks @Andriy_Konoz. Please let me know what you find out. I am planning on leaving logging set to Error and if we have an outage that is on Backendless we’ll see what the charges end up and we can address those with billing.
While your suggestion of turning off logging and building my own logging does work, it doesn’t seem in line with your marketing.
Everything you need to build and run high-performance apps, all in one place.
While your suggestion of turning off logging and building my own logging does work, it doesn’t seem in line with your marketing.
It seems to me that there is a misunderstanding. Under “custom logger” I meant Backendless custom logger. To do that you need to use this block and provide some name for your custom logger.
As I said before, my recommendation is to turn off “SERVER_CODE” logger in your app and use explicit logging when you need it. With this adjustment you will not be overcharged for additional logging even if platform encounter some outage.
However, this doesn’t give me any tracking or accountability if Backendless is down.
For example, if my CS team comes to me with reports of an issue and the logs are clear, I have no idea what happened. I want to know when Backendless is down.
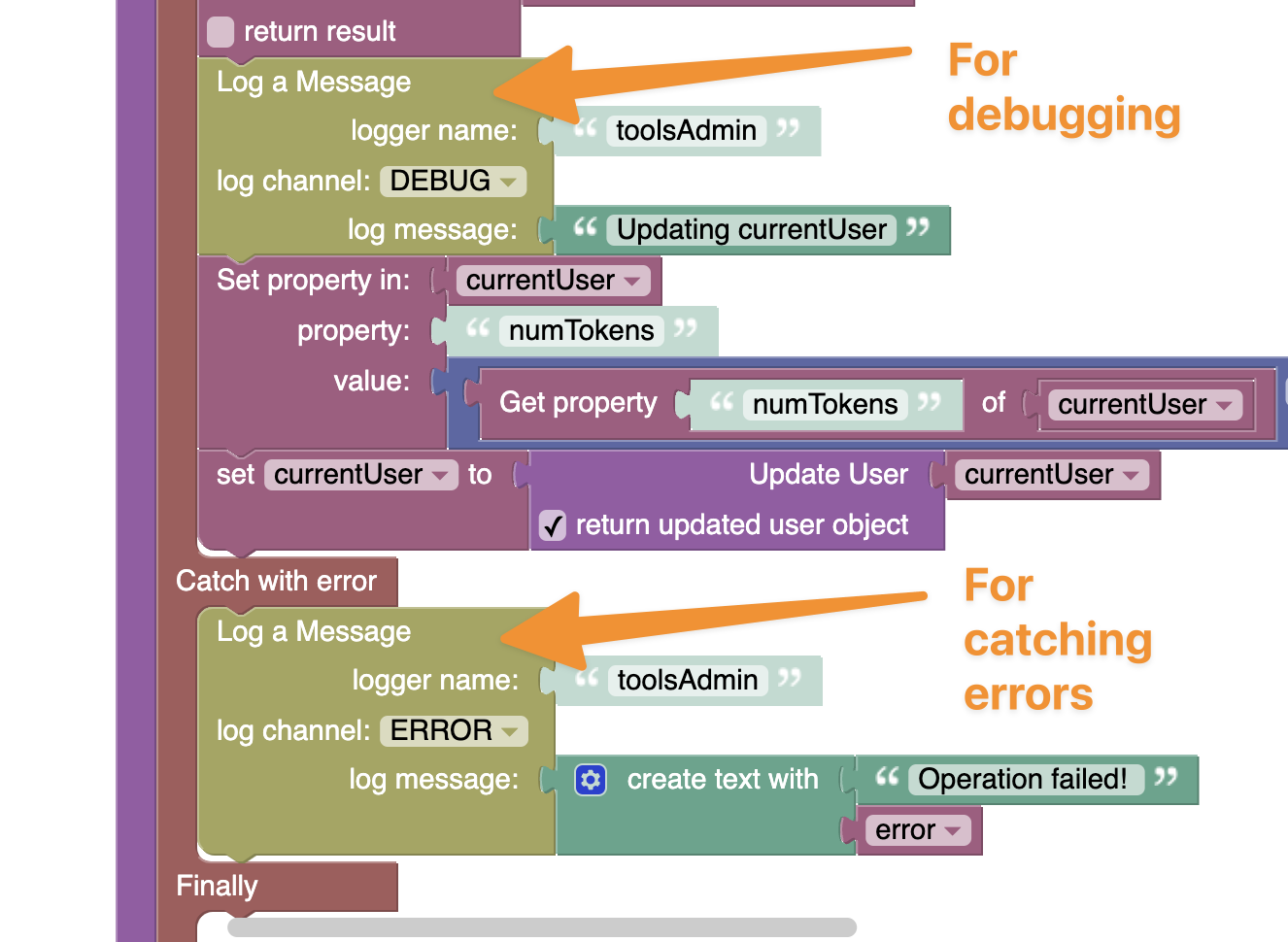
I use this approach that Marks recommend here, with try/catch clauses, for all my work, and it gives very good flexibility and control!
A tip also is to have loggers in place in your code with a lesser level (DEBUG) that you can turn your named logger down to in cases where you need to review something:
Then you just adjust your logging level, and your log output just updates accordingly. As Mark said, these log calls will only count towards API calls when the logging level is matched, so they do not impact when the logging level is raised back to e.g. ERROR.