If the following discovery is true, I am done with Backendless! For a month now I am working around my way of the time limit for a task. 5 seconds then the task ends! And no, buying more time from you guys is not an option. Why should I? I am already paying. I am a small customer and I don’t have endless budget!
Anyway, I found solutions, with asynchronous calls and recursion. It worked. But suddenly it doesn’t work anymore. Why? Well see the following screenshot!
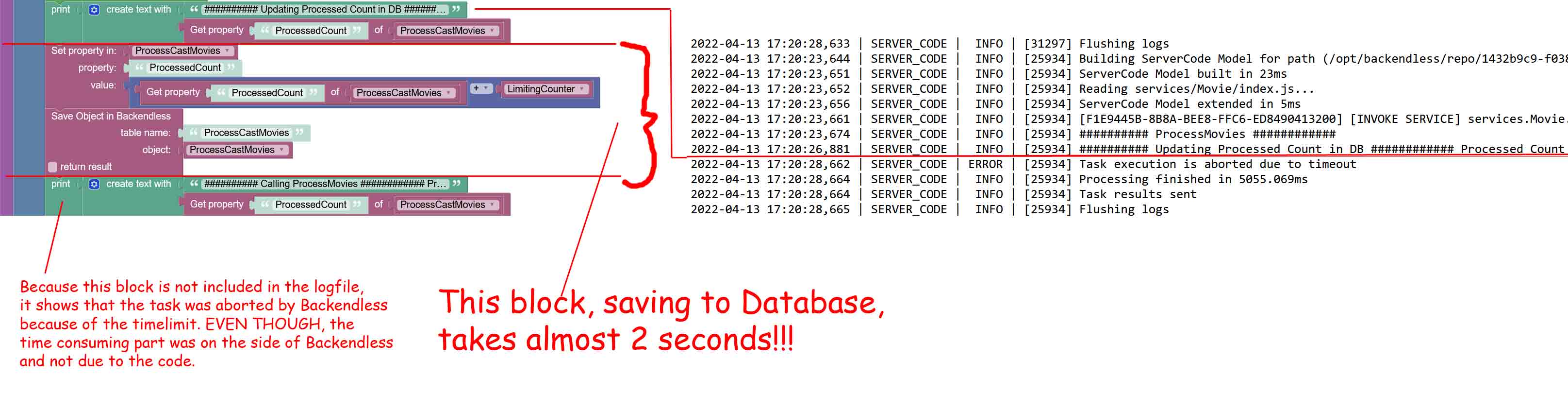
Because it takes TWO SECONDS to save ONE RECORD into your database, my task runs into a timeout. This is not my fault! If you guys put a time limit on my tasks, you have to give me a calculable, reliable time, for how long you take to process data! If you go over that limit, you can not deduct this from MY TIME!!!
Imagine, if I would buy more time from you, and then you guys just burn that through YOUR SERVER TIME?!
First of all, let’s calm down. Problems are rarely solved when we get mad or angry.
To diagnose this further, I recommend running a test of saving an object in the same table using REST Console. Have you tried that? If you have, how long does it take to do so?
Additionally, knowing the following, might help with resolving the issue:
how complex is the object?
Do you have a sample of what is being saved?
Thank you for your reply Mark! I really appreciate. And I agree!
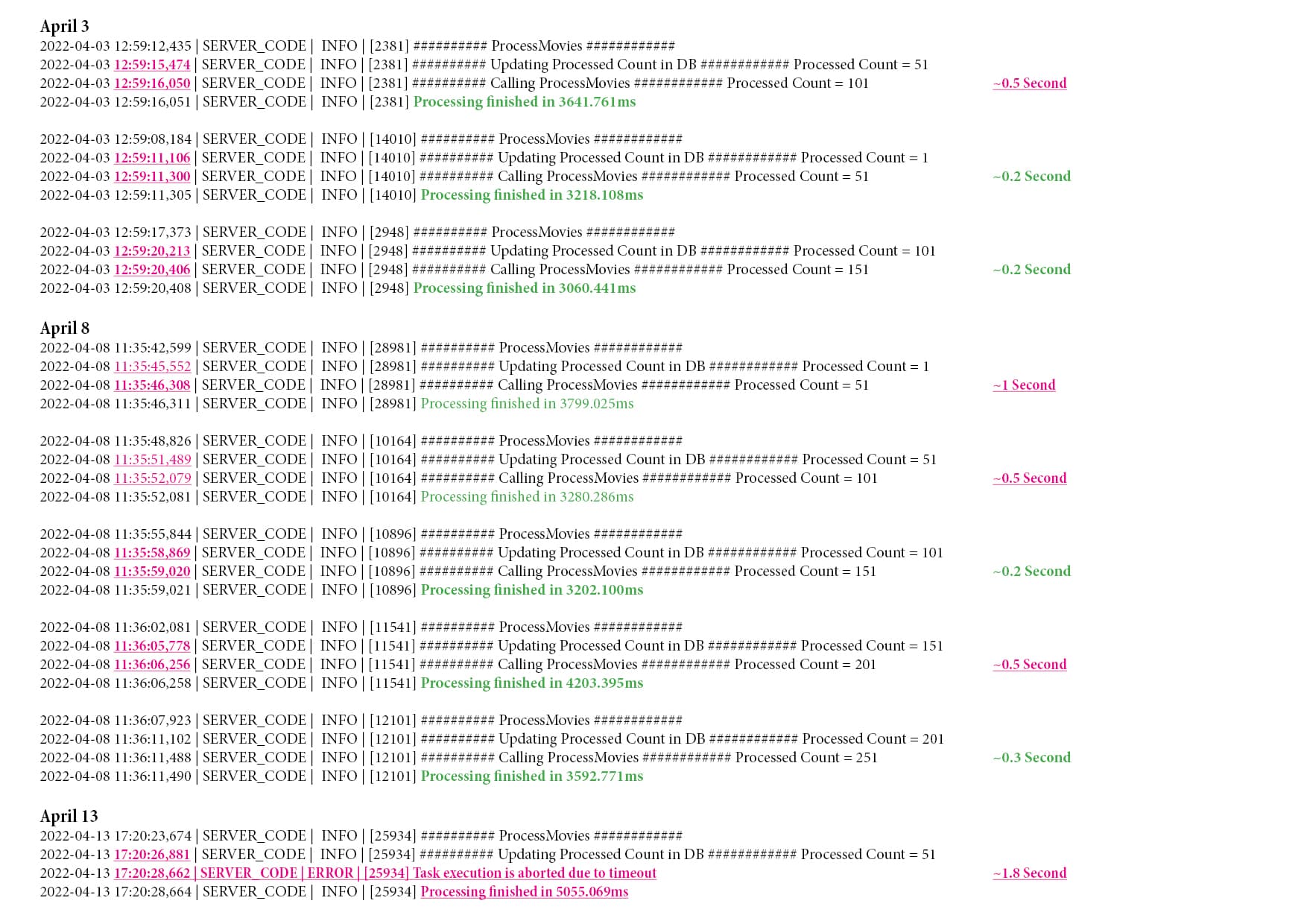
But this does not solve the core issue. I need reliable processes. I am testing this process now for many weeks with always the same data. The problem is, that it’s suddenly not working anymore, because the Backendless database saving process suddenly takes up 1.8 seconds instead of the usually 0.2 - 1 seconds.
So I would say the logfile answers your first question. It usually takes 0.2 - 1 seconds. Not through the REST Console though, but through the regular workflow, and its really just one record with a handful of fields. It has one larger property with a JSON in it, that has about 108k characters. But as I said, I am testing with the same data again and again, and so far it was never a problem.
In my understanding, based on the logfile data, the focus should not be on the complexity of the object but rather on the fluctuation of time consumed by the “Save Object in Backendless” process when using exactly the same data. For the following reasons:
The data in the logfile shows clearly that usually the time is under 1 seconds
The logfile also shows, that there are great fluctuations within the exact same process of saving an object to the database, and exact the same data.
This is generally not concerning to me, but it becomes concerning, when there is an artificial limit on the process and if that limit runs into a greater fluctuation which then brings the whole process to a halt.
This makes the system very unreliable and it would need a lot more workarounds from my side to make this wobbly system process safe.
Basically what this means is, that I would have to create a process around each little step, even the ones that are built in processes from Backendless such as saving a simple object to a database. Then check in that process if it is properly saved or not. But how would that be even possible if I don’t have anything reliable to begin with? Caching?
I also can’t try/catch this problem, because your artificial limit takes down the whole process
So in order to really make this process safe, I would have to build an external service that monitors the Backendless process. But then what’s the point of even using Backendless?
A simple solution for this can be implemented from your side. Do not deduct from my server time, when your server processes take longer than usual. And if things really go terribly wrong on your side give me an exception to catch. This way I would still have enough time to do something with it before my server time is up.
The first priority is to determine what causes the slow down. Having a specific payload would help us narrow it down, that’s why I asked about reproducing in rest console.
What is your application ID?
What is the name of the table?
Are you saving a new object or updating an existing one?
Does every record in the table has ~100k json value?
I won’t make any changes until I get feedback. The actual status of the record is after a successful run. It’s always the same record. What my workflow does is:
Load the whole record
Iterate over the JSON list in “castMovies”, starting with the counter at “ProcessedCount”
Stop after 50 items and write the current counter into “ProcessedCount”
Then call itself again (recursion), if “ProcessedCount” < “TotalCount”
This is the solution I found to work around the 5 second limitation in the first place!
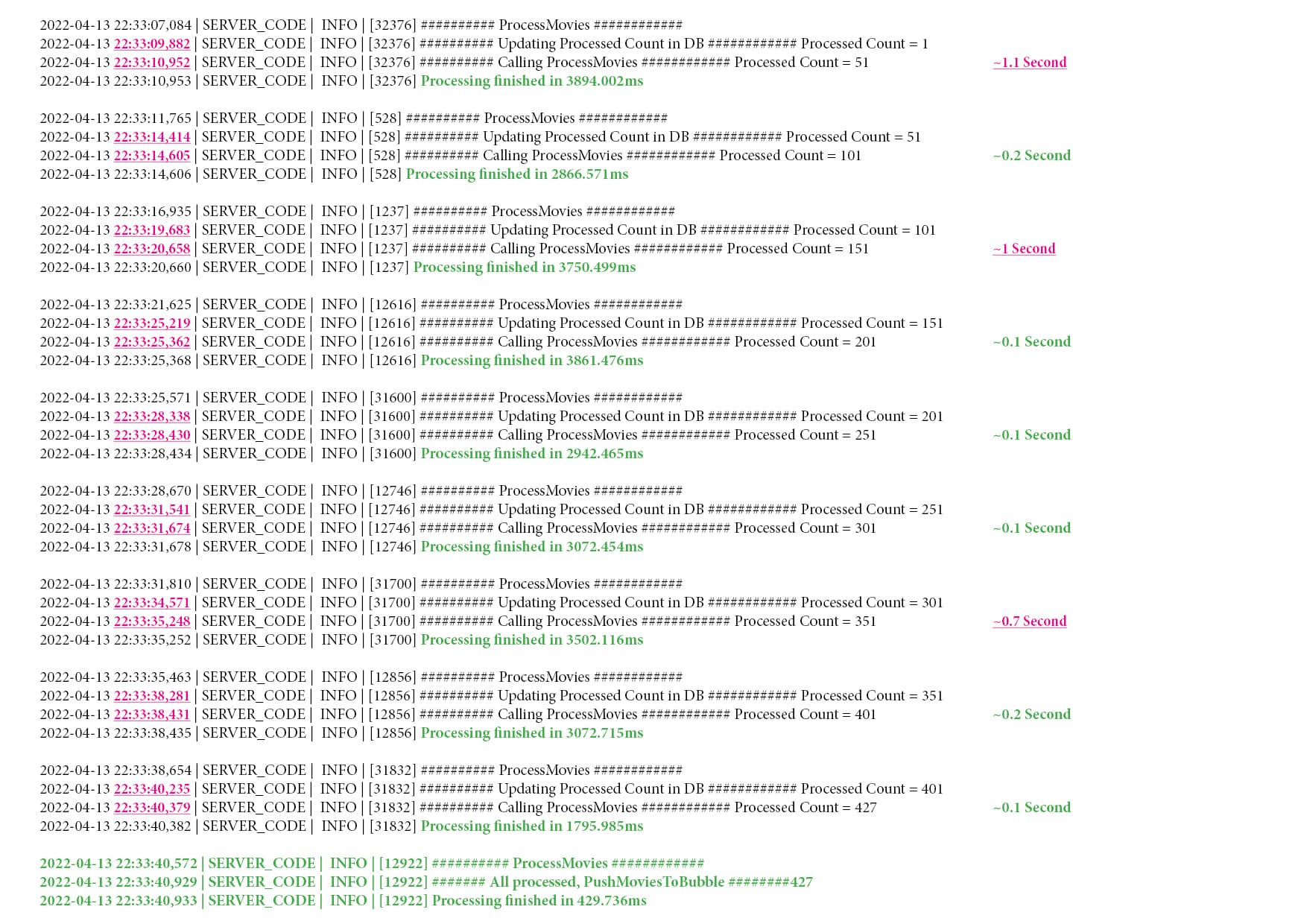
What causes the slow down must be something in the internal processes of Backendless, as proven by the logfile. I just tested it again and it ran through without any problems. I have not changed the code since, nor is the payload different.
In the finished version it will change all the time. It is part of the process data. But for testing purposes I am using always the same data. Exactly for situations like this, to be sure it’s not the data that causes the issue, because it worked with this data before.
The overall process looks like this:
In an app on Bubble.io I have a list of movie actors
I click on an actor to get their filmography
This request is sent to the Backendless app, which downloads the necessary data from IMDb API, processes it (which is the castMovies field) and sends the results of movies to the app in Bubble.io
So depending on which actor I choose, the data will change.
But as I said, I am always testing with Keanu Reeves
For now, I won’t make any changes, neither code nor data, in case you want to test something with the existing situation, until I have feedback.
I reviewed the implementation and made a few observations. Something that stood out immediately is the time it takes to update an object when the JSON payload (the castMovies column) is included is about 2.5 times slower vs when JSON is not there. Here are the time for comparison:
There are two highlighted requests here: the first one (1.18 seconds) is when an object is updated and the payload includes JSON. The other one (410 milliseconds) is when an object is updated without JSON column.
This made me think that the current approach is not very efficient. What you’re doing is passing that rather large JSON array back in forth between the Cloud Code and database for the purpose of processing it in the cloud code. And the purpose of that is to fetch data from IMDB for each element in that JSON array.
I thought about what would be a better solution that would remove some complexity. And by complexity, I mean all the recursive calls you have to do. Here’s how I would go about implementing it:
Rather than storing the JSON list as a column in the record, I’d process the JSON (wherever it comes from) and use the Bulk Upsert block to create individual “movie” objects in Backendless. Basically, every object in JSON would end up being a record in the Backendless database. When you process the JSON list in a loop, use the Bulk Upsert block for every 100 objects in the source list. Every object would also need the processed boolean column with the default value set to false.
Now, the movie objects from the original JSON are in the database, the question is how to organize getting data from IMDB. To do this, I’d create a timer in Backendless (you can do it in Codeless) and set up a schedule for it. The timer wakes up and fetches 50 movie objects where processed = false. For each object you fetch data from IMDB and do what you’re doing now. As soon as the object is processed, meaning you got data from IMDB, you update that object in the database and set processed as true. The timer will handle as many objects as it can in a single cycle, however, the same timer will wake up again based on the schedule you came up with and will continue processing the objects. Btw, if the timer gets an empty collection, it means there are no un-processed objects, so the timer would just quit.
It still doesn’t address the core issue I was describing and it’s also not congruent with my analysis.
In my tests, as shown in the two logfile screenshots I posted, it often takes only ~0.2 seconds to save the whole record back into the database, including the large JSON. I don’t know how you came up with your comparison. Did you test it a few times, to see if you get consistent results?
Again here is the core issue I am trying to address:
The “Save Object in Backendless” Process step fluctuates greatly in the time it takes to save data, even with the exact same data. This means it is not reliable. And on top of that, this fluctuation is deducted from the server time I am buying from you guys. Or in other words, the price/value I am getting from your business model fluctuates with each iteration. Not because my data fluctuates, but because your infrastructure fluctuates!
I am aware that I can optimize it even more. Which the timer solution is certainly not an option to choose from, since it only executes every 60 seconds. That’s quite a long time for a user to wait until his movies are loaded! Not taking in consideration that there are several iterations needed until 450 movies are processed…
And your approach in general isn’t working either, because no matter how you turn it around, you have to process in batches and then save the counter back to the database. But if it’s not reliable how long this will take, it might as well abort, because of your artificial limit that also does not take in consideration your very own server time. And then the counter is wrong and then you end up with a corrupt process state!
I really could build a whole process engine around this stuff and it would work eventually. But why all this effort if it really boils down to one simple core issue as addressed above? An issue that is not on my end but on yours!
This also isn’t about how to optimize. This is really about you guys killing my process after you have eaten up my server time with your slow database process!
The limit we impose is the time that is spent inside of your logic and any APIs it uses.
I tested the invocation multiple times and the times I get are consistent. With JSON included in the payload it is 2.5 times greater than without it. I believe storing 80k worth of JSON in the database and then sending it back and forth for the sake of analyzing it in Cloud Code is a bad design decision. It penalizes you with the overall performance and forces you to jump through the hoops with recursion. At the very minimum, I’d change it so that JSON is stored as a file (there is API for it) so it is loaded only once.
Since the logic runs in a shared hosting environment, it may happen that an invocation takes more time than at other times. For instance, if there is a general spike of activity across multiple apps hosted on the plarform, the infrastructure responds by allocating more servers, memory, CPU, etc. When it happens and until additional resources become available, invocations may take longer.
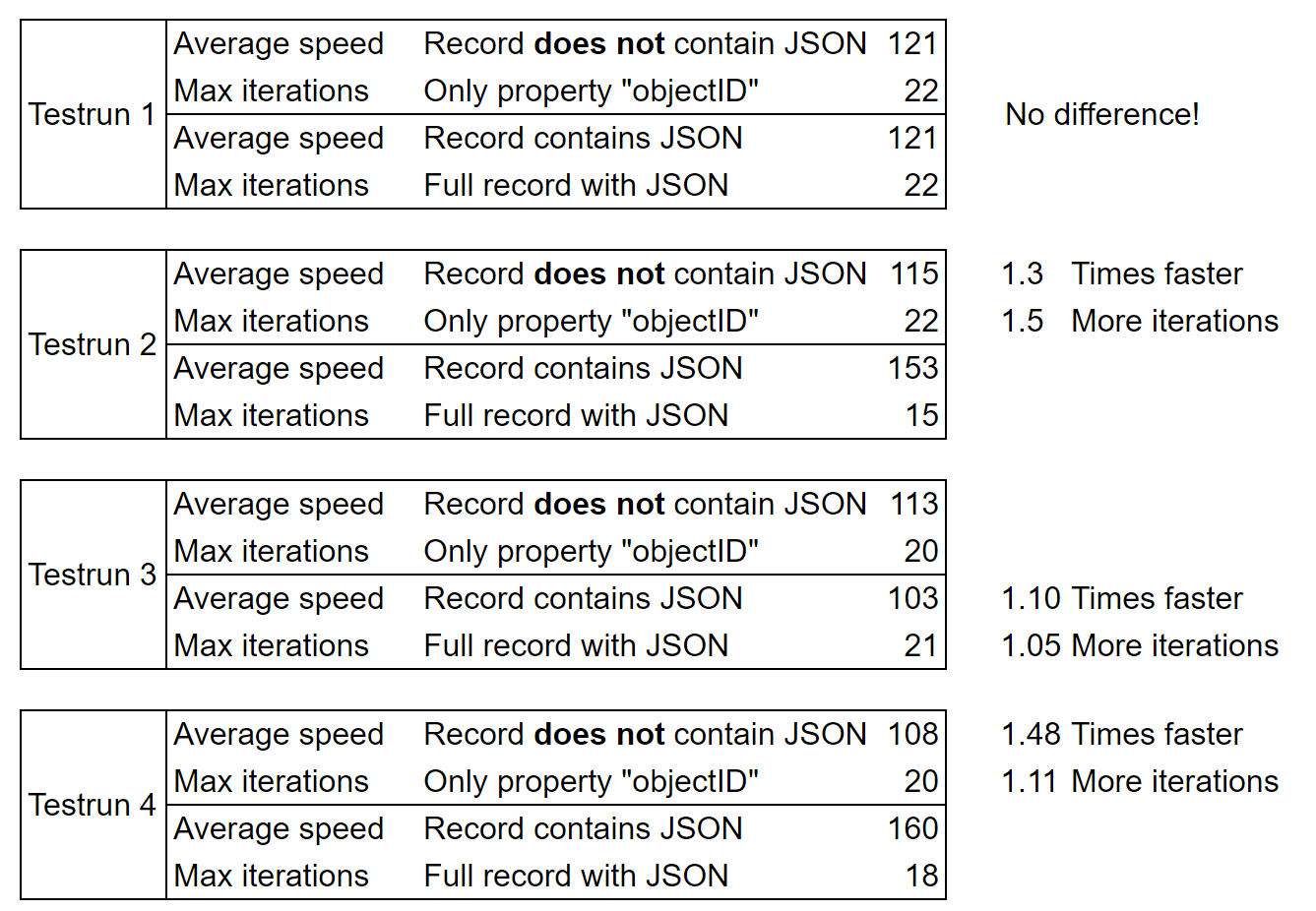
The result shows that indeed, sometimes it is slower with the JSON. But not always. Sometimes its the same, and sometimes its even faster with the JSON! Keep in mind, that this is loading the JSON and saving it back to the database. Same speed or even faster…
By no means it’s 2.5 times slower, and it again shows the fluctuations in the infrastructure. You can test it yourself if you like:
Application ID: 1432B9C9-F038-C3DB-FF2C-0826974E8800
API Service: TestBackendlessSpeed/TestDatabaseSpeed
But anyway, I guess at the end of the day we all have to work with whats available. I did my best to point out something.
This guy Hans is raising good points. I came across this post as i am searching for solutions due to very small limited time of execution. I need to make close to 1000 saves once a day and every save takes anywhere from 400 to ms to 600 ms (and sometimes more). This only allows me to do handful of saves within the time limit due tk backendless its own operation time. Backendless operation time should jot be calculated from script time
No two saves in different apps are the same. How complex is the data structure being saved? How do you measure the time? Invocation in your code or complete round trip from the client side?
Have you tried optimizing the logic? For example, using bulkUpsert or using transactions?
There is a lot that can be done to make it very fast. Our internal monitoring system shows that individual save operations running in cloud code are as fast as 50-70ms. However, as I said, no two saves in different apps are the same.
First Merry christmas
Second thanks Mark for your answer. Your support is major point why many lovebyour service .
Let me tell you what am trying to do and mg observation. I will create a new thread so threads are not mixed up