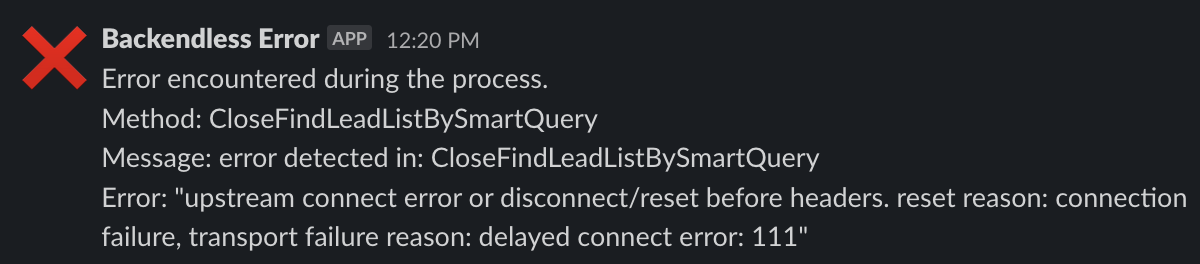
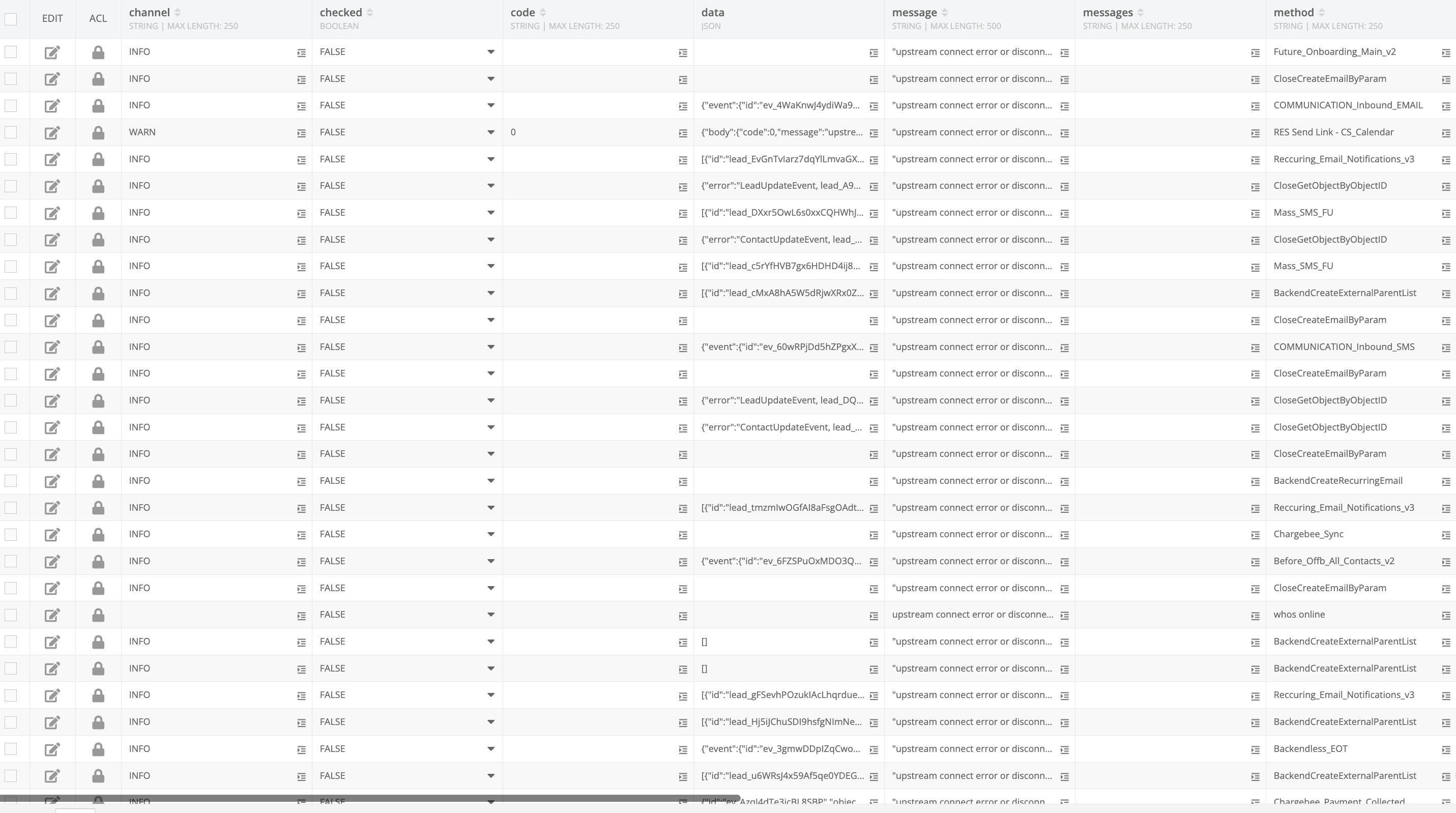
We are getting some errors with the message: “upstream connect error or disconnect/reset before headers. reset reason: connection failure, transport failure reason: delayed connect error: 111”
It is happening on more than one method. I cannot find a root cause yet and wanted to ask if there are any known performance issues at this time or if the error message is known to you.
Online documentation makes this seem to be related to the port used. This is not something we actively manage in our app.
I will be needing your help as I cannot find any common pattern that will allow me to reproduce the issue.
May I ask the following questions that may help me reproduce:
Does the phrase ‘upstream connect error or disconnect/reset before headers. reset reason: connection failure, transport failure reason: delayed connect error: 111’ correspond to a Backendless Error message?
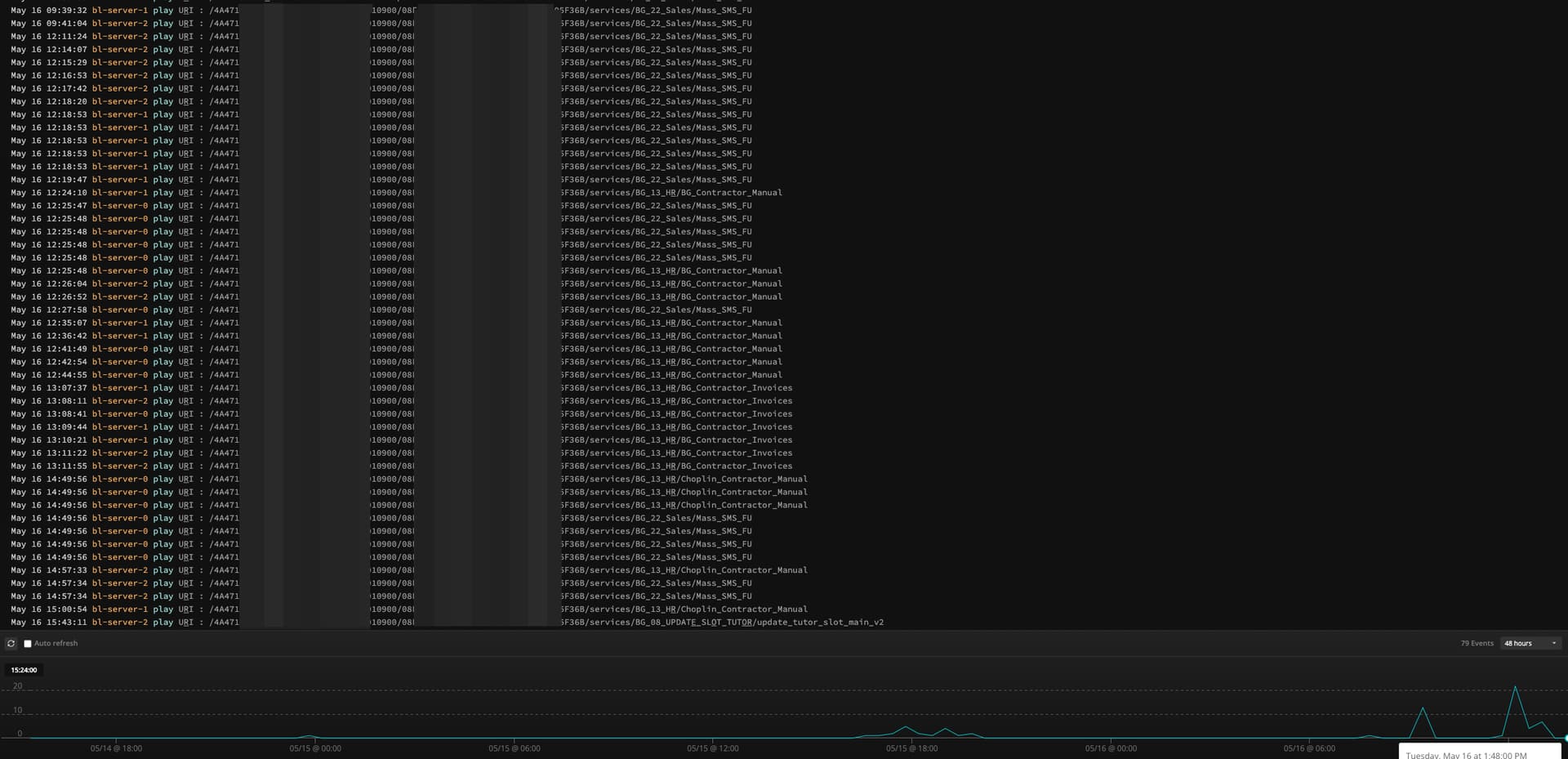
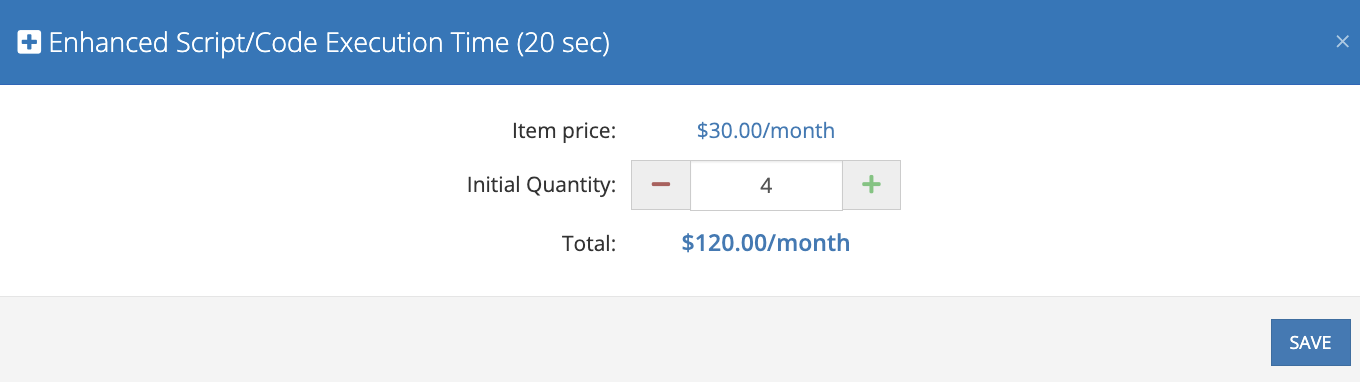
You mentioned that we have services that execute above 30 seconds, yet with our enhanced scriot/code execution time, you are able to execute 85 seconds. Does that mean that the 79 requests you mention above are most probably > than 110 seconds (30sec + 4x20 sec enhanced script)?
This error might mean that the connection cannot be established, or the connection was refused by the server. Is this always something on our side, or might it be on your side?
Some of the errors are coming from services that are very short, not exceeding 110 seconds for sure. Is there any other reason why our API calls will be rejected by Backendless? Is there anything regarding the ports used for the API services, IP addresses of the Backendless servers, or anything similar that may cause errors?
Can you advise of any other ideas I might try to reproduce the issue?
We are getting lots of random errors and I am not sure where to start looking. Any guidance would be appreciated.
If the problem was with accessibility, then you would never be able to get access to the Google Drive API, yes, I understand that some requests go through.
We don’t block in our firewall external resources, you can connect to all of them, but i’m check it manually and access to google drive api is available from our side.
This is a possible option if there is some limit on the number of connections from one IP to the Google Drive API itself. But I think they should issue an error code and a alert message about exceeding the connection limit.
Do you have a counter of how many requests you make (from business logic) to Google API, for example, per minute?
Yes we have that. There are instances that we exceed the limit but they are not correlated with the errors above. A lot of the methods that are exhibiting this issue are not accessing the Google API at all. Is there some part of the error that makes you think it is the Google API?
This document is not related to Backendless. But may you know anything about “the port our application exposes”, “how to manage the port our application is listening to”? Is there any setting related to this?
18:30:25.572 | SERVER_CODE | INFO | [2457769] ResponseError: upstream connect error or disconnect/reset before headers. reset reason: connection failure, transport failure reason: delayed
connect error: 111 at checkStatus (/usr/local/lib/node_modules/backendless-coderunner/node_modules/backendless-request/lib/request.js:330:9) at processTicksAndRejections (internal/process/task_queues.js:95:5) { code: undefined, status: 503, headers: { ‘strict-transport-security’: ‘max-age=31556926; includeSubDomains’, ‘content-length’: ‘145’, ‘content-type’: ‘text/plain’, ‘ratelimit-limit’: ‘60’, ‘ratelimit-remaining’: ‘41’, ‘ratelimit-reset’: ‘1’, ‘x-ratelimit-limit’: ‘60, 60;w=1, 100;w=1’, ‘x-ratelimit-remaining’: ‘41’, ‘x-ratelimit-reset’: ‘1’, vary: ‘Accept-Encoding’, date: ‘Tue, 16 May 2023 15:30:25 GMT’, server: ‘envoy’, connection: ‘close’ }, body: ‘upstream connect error or disconnect/reset before headers. reset reason: connection failure, transport failure reason: delayed connect error: 111’ }
This is an explanation of the error from the side of the application that works on the side of the Google Drive API, that is, they also have a proxy server that proxies to many application servers and the upstream error just comes from the side of the Google Drive APi infrastructure, that is, their server reports a 503 error because the backend of the application close connection due to errors or other factors.
From our side receive the full response provided by the server to which the connection was established. I can say for sure that in our infrastructure we do not use envoy proxy, and in this case the error responses come from the envoy web server.
I dug deeper, but everything points to an error on the part of the infrastructure where connecting, that is, the Google Drive API.
Perhaps the error began to appear after updating some parts of the Google Drive API infrastructure and after some time they will fix it, but you should create a ticket and describe the problem.
If the error appears in the code where there are no requests for the Google Drive API, then we need to understand to which external resource the connection is being created. So it is necessary to figure it out, I agree with you.
Perhaps these are requests to some external components of CodeRunner itself, I will now try to clarify with our developers.