Hi there everyone!
I’ve got a case where data rows are added by multiple sources - and some duplicates are added.
It’s not efficient to check for an item’s existence before adding a new row as the duplicates are very infrequent.
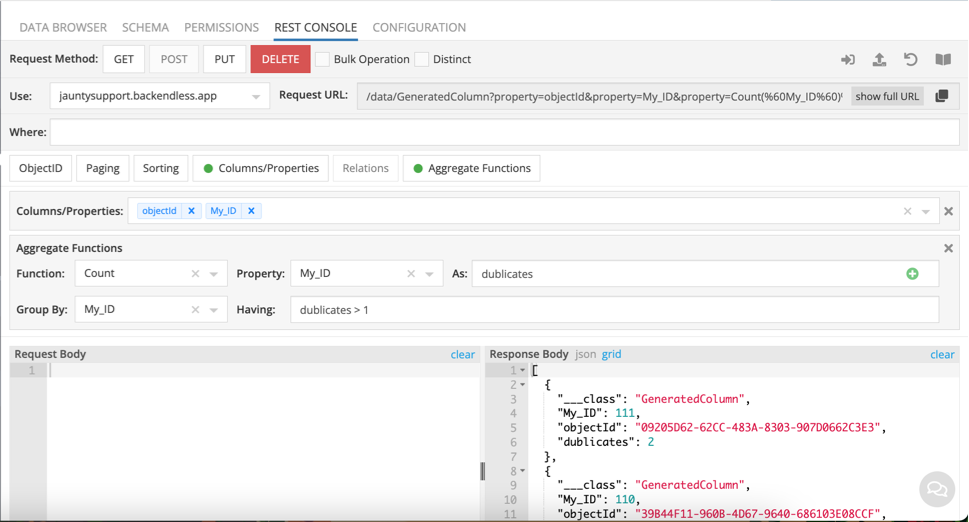
I’m looking to periodically check and remove duplicates. The current solution I have is to create a generated column which counts the repetitions of the value in a particular field.
Basic example:
My_ID column may contain -
110
111
112
111
113
114
This generated column should show 1 for all except ‘111’ which would show two - there are two occurrences.
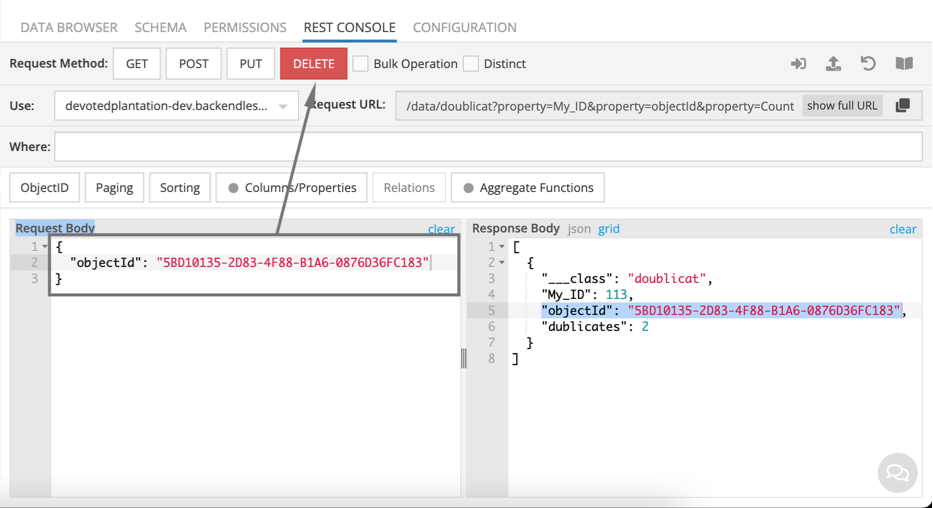
I can then use a couple of quick calls to find and remove duplicates.
Assuming this is possible, I can’t find the syntax to do so in a generated column. Can anyone help point me in the right direction please?
(or if there’s a solution I’m missing, please do let me know!)
Thanks!
Rob