Relational data support is one of the strongest points of the Backendless database system. In some cases, you want to bootstrap your development by bringing some sample (or existing) data into Backendless. This can be done using the import function available on the Manage > Import screen in the Backendless console:
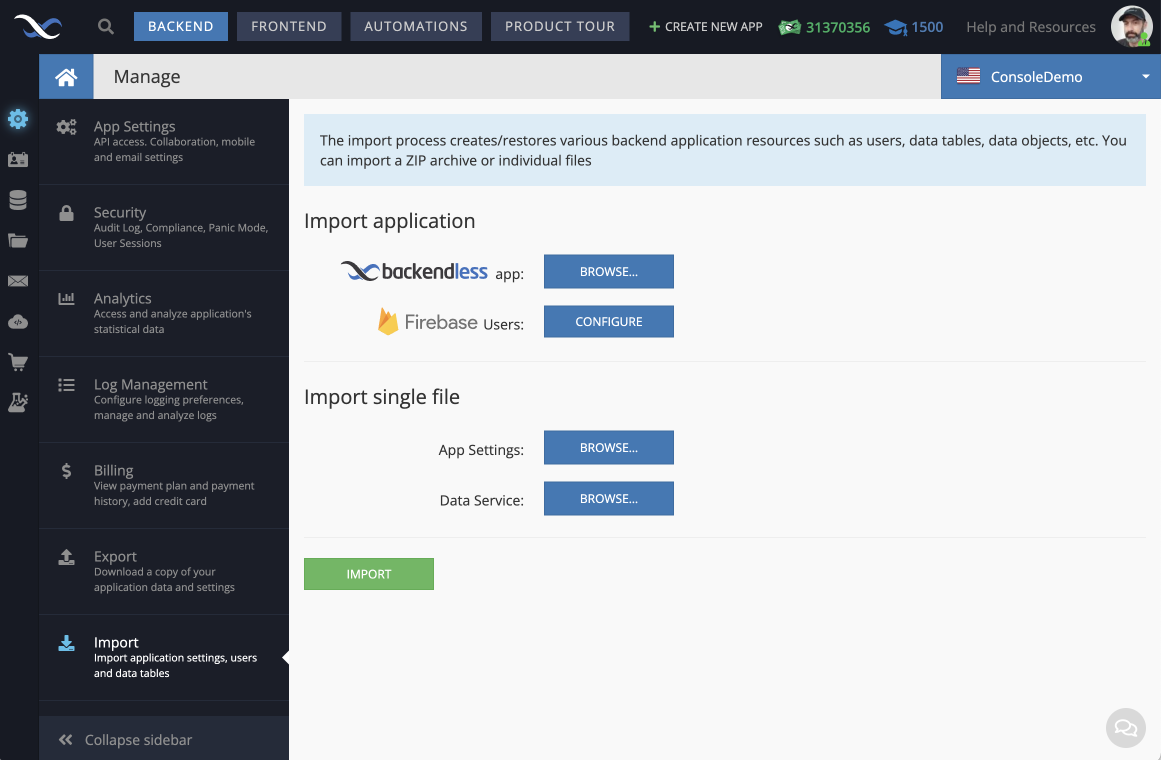
When you import data into Backendless database, a single CSV file brings data into a single database table. If the table does not exist at the time of the import, it will be created with the same name as the CSV file name. Otherwise, the platform will use a table that has the same name as the name of the CSV file.
Individual CSV files can be imported using the BROWSE... button located at the bottom (right where it says Import single file and then Data service. This option supports multiple file selection and is the recommended way to import single or multiple data (CSV) files.
In this article, I would like to review the format of the CSV files for the scenario when your database tables have relations. Consider the following database schema:
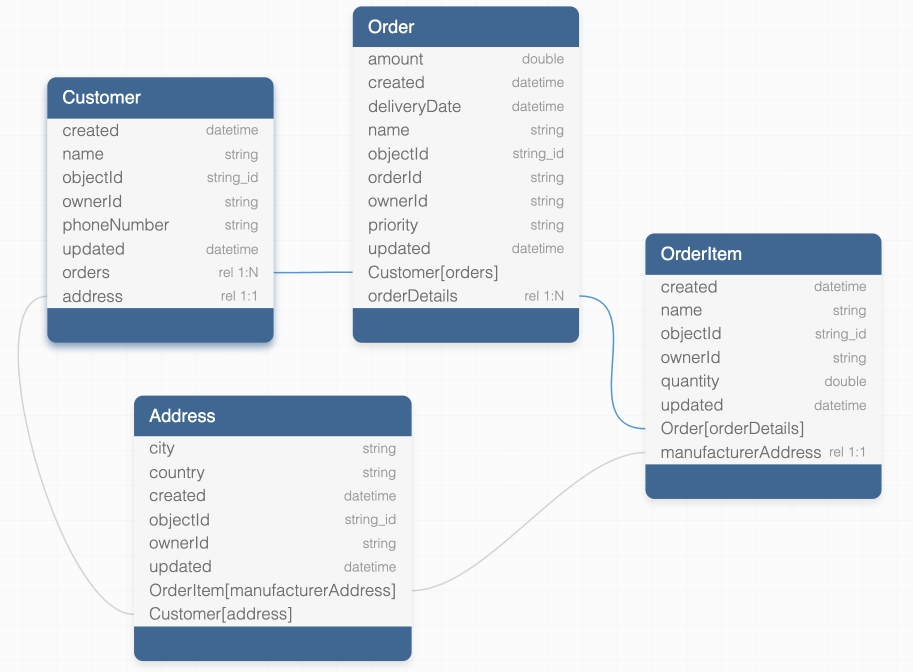
The schema features different types of relations, including both one-to-one and one-to-many relations.
Below is the sample data as we expect it to appear in Backendless:
Customer table:

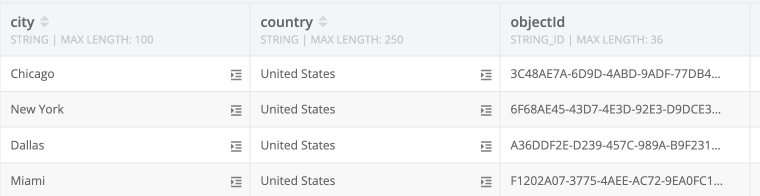
Address table:
Order table:

OrderItem table:

Let’s review the source CSV data used to populate the database:
Customer.csv:
name,phoneNumber,"objectId({""type"":""STRING_ID""})","address({""type"":""RELATION"",""relatedTable"":""Address""})"
"Joe","555-1212","765EF32B-A715-4C54-84D6-EB1E8B622121","F1202A07-3775-4AEE-AC72-9EA0FC1BC54C"
"Bob","555-4343","8D79BA7D-ACE3-47DC-9D90-B5985CDDD363","A36DDF2E-D239-457C-989A-B9F2319A58BC"
"Jack","555-9898","FC584FF8-E44B-408D-B9F4-F7CF387CD538","6F68AE45-43D7-4E3D-92E3-D9DCE37F0EA3"
Address.csv:
city,country,"objectId({""type"":""STRING_ID""})"
"Chicago","United States","3C48AE7A-6D9D-4ABD-9ADF-77DB456BA428"
"New York","United States","6F68AE45-43D7-4E3D-92E3-D9DCE37F0EA3"
"Dallas","United States","A36DDF2E-D239-457C-989A-B9F2319A58BC"
"Miami","United States","F1202A07-3775-4AEE-AC72-9EA0FC1BC54C"
Order.csv
deliveryDate,name,orderId,"priority({""type"":""STRING"",""dataSize"":250,""expression"":""CASE\n WHEN DAYOFWEEK( deliveryDate ) IN (2,3,4,5,6) \n THEN 'HIGH'\n WHEN DAYOFWEEK( deliveryDate ) IN (1,7) \n THEN 'MEDIUM'\nEND"",""dynamicProps"":{""localData"":{}}})","objectId({""type"":""STRING_ID"",""dataSize"":36})","orders({""type"":""RELATION_LIST"",""relatedTable"":""Customer""})"
"2022-03-12T06:00:00.000Z","Order A","050722-AK1","MEDIUM","11F0354B-5F20-4AEE-A511-7E26155DF6BE","765EF32B-A715-4C54-84D6-EB1E8B622121"
"2022-03-24T05:00:00.000Z","Order B","061821-CV1","HIGH","3A04D2B6-44D3-4A08-AC56-A316366C5069","8D79BA7D-ACE3-47DC-9D90-B5985CDDD363"
"2022-05-27T05:00:00.000Z","Order C","090819-CV2","HIGH","4D8BDF3E-ABB7-4EC6-9B46-C235FCB07077","765EF32B-A715-4C54-84D6-EB1E8B622121"
OrderItem.csv
name,quantity,"objectId({""type"":""STRING_ID"",""dataSize"":36})","manufacturerAddress({""type"":""RELATION"",""relatedTable"":""Address"",""relationIdentificationColumn"":""city""})","orderDetails({""type"":""RELATION_LIST"",""relatedTable"":""Order""})"
"Paper Towels",10.0,"43925FB1-1F7A-41E6-B8C5-0FB5F8566FE3","6F68AE45-43D7-4E3D-92E3-D9DCE37F0EA3",null
"Paper Towels",10.0,"43925FB1-1F7A-41E6-B8C5-0FB5F8566FE3",null,"4D8BDF3E-ABB7-4EC6-9B46-C235FCB07077"
"Paper Towels",10.0,"43925FB1-1F7A-41E6-B8C5-0FB5F8566FE3",null,"3A04D2B6-44D3-4A08-AC56-A316366C5069"
"Paper Towels",10.0,"43925FB1-1F7A-41E6-B8C5-0FB5F8566FE3",null,"11F0354B-5F20-4AEE-A511-7E26155DF6BE"
"Bathroom Tissue",20.0,"91026D1C-217E-4078-AEDD-2DBDBD10BF7E","A36DDF2E-D239-457C-989A-B9F2319A58BC",null
"Bathroom Tissue",20.0,"91026D1C-217E-4078-AEDD-2DBDBD10BF7E",null,"4D8BDF3E-ABB7-4EC6-9B46-C235FCB07077"
"Bathroom Tissue",20.0,"91026D1C-217E-4078-AEDD-2DBDBD10BF7E",null,"3A04D2B6-44D3-4A08-AC56-A316366C5069"
"Bathroom Tissue",20.0,"91026D1C-217E-4078-AEDD-2DBDBD10BF7E",null,"11F0354B-5F20-4AEE-A511-7E26155DF6BE"
"Pencils",20.0,"F7A01263-FE23-4ED5-A7C1-342C373BFA4F",null,"3A04D2B6-44D3-4A08-AC56-A316366C5069"
"Pencils",20.0,"F7A01263-FE23-4ED5-A7C1-342C373BFA4F","6F68AE45-43D7-4E3D-92E3-D9DCE37F0EA3",null
A few things about expressing relations in the CSVs to point out:
- For the 1:1 relations, the parent table/CSV reference child objects - see Customer.csv. You will find the following column declaration for the 1:1 relation with the
Addresstable:"address({""type"":""RELATION"",""relatedTable"":""Address""})" - Values of the child objects for 1:1 relation are specified in the parent CSV file. You will see there are
objectIdvalues of the Address objects inCustomer.csv. - For the 1:N relations, it is done in reverse - child records reference it’s parent. For example, see
Orders.csv. You will see the following column declaration:
Keep in mind that In this case, the column is created/used in the parent table."orders({""type"":""RELATION_LIST"",""relatedTable"":""Customer""})"
Most of the columns declared in the sample CSV files above do not have any additional meta information. In this case, when you import the files, Backendless will prompt you with the following screen where you can specify the data types for each column. For example, below is a screen you will see for Customer.csv referenced above:

A similar screen will be displayed for each imported CSV. Make sure to assign the right data types and click
FINALIZE IMPORT.
Alternatively, when you import a single zip file, Backendless will not prompt you to identity data types and will assign the STRING data type to all columns (except for the relations). You are welcome to experiment with the sample data shown above by importing the archive file referenced below:
Sample-Import-Data.zip (3.7 KB)
Hope you found this helpful. Any comments and feedback is always appreciated.