I am getting the following error when I try to import my csv file.
Unable to create a table with columns from the CSV file since the total size of table columns exceeds maximum allowed row size. Try reimporting the file with the following changes:
There are a lot of columns in this file and all but two are type string ( 1 - 100 chars) so I don’t think I should be using type text for any of these.
Note: I can’t control the format of the csv files I receive they have a lot of fields. I was planning to import them and then do a data conversion to move the data in the imported csv into a more functional table structure
ref (What is best practice for high number of properties - #11 by hharrington )
for how I planned to do this.
Now I’m guessing I’ll need to manually break the csv into multiple tables and import each separately (so I would need to know the maximum allowed row size or is there a better way for me to do this?
thanks,
H
Hi H,
The maximum allowed row size is 65K. Keep in mind that the data types use up the space as listed below:
- INT - 8 bytes
- DOUBLE - 16 bytes
- DATETIME - 8 bytes
- BOOL - 4 bytes
- STRING - 500 bytes
- TEXT - 20,000 bytes
A best practice is to pre-format your CSV so it has the same structure as the final data table in your schema.
Regards,
Mark
doing some quick math,
65k * 1000 b/k /row / 500b/string = 130 strings / row ( assuming k = 1000 bytes )
my csv file has 40 fields (columns ) so it should fit.
as a test, I cut down my csv file to two lines (header and one data row) there are a total of 274 chars in all fields combined. I know this most likely does not matter since they will be mapped to a string of 500 chars, but I got the same error as above.
my table is there with all the fields, but there are 0 rows in the table.
what am I missing?
thanks
HH
What are the data types of the columns in your CSV? Are they all strings?
The actual size of the data fields in your CSV are not relevant. You could have a string of 1 byte, but the database will still allocate the space for 500 bytes for that field.
Do you have a sample CSV file you could share?
Sure,
The file below gives me this error.
IMPORT_DATA Import of tables failed: Unable to create a table with columns from the CSV file since the total size of table columns exceeds maximum allowed row size
and when I check it, there are 0 rows but the table with all the fields is there.
Samp_info_ky_test_one_row.csv
Thanks,
H
I was able to reproduce the error. I will have to pass it on to the product team for investigation. For now your best option is to set the data type and length restriction for each column to avoid whatever restriction is there.
Thanks!
I’ll test that out. and see how it goes.
H
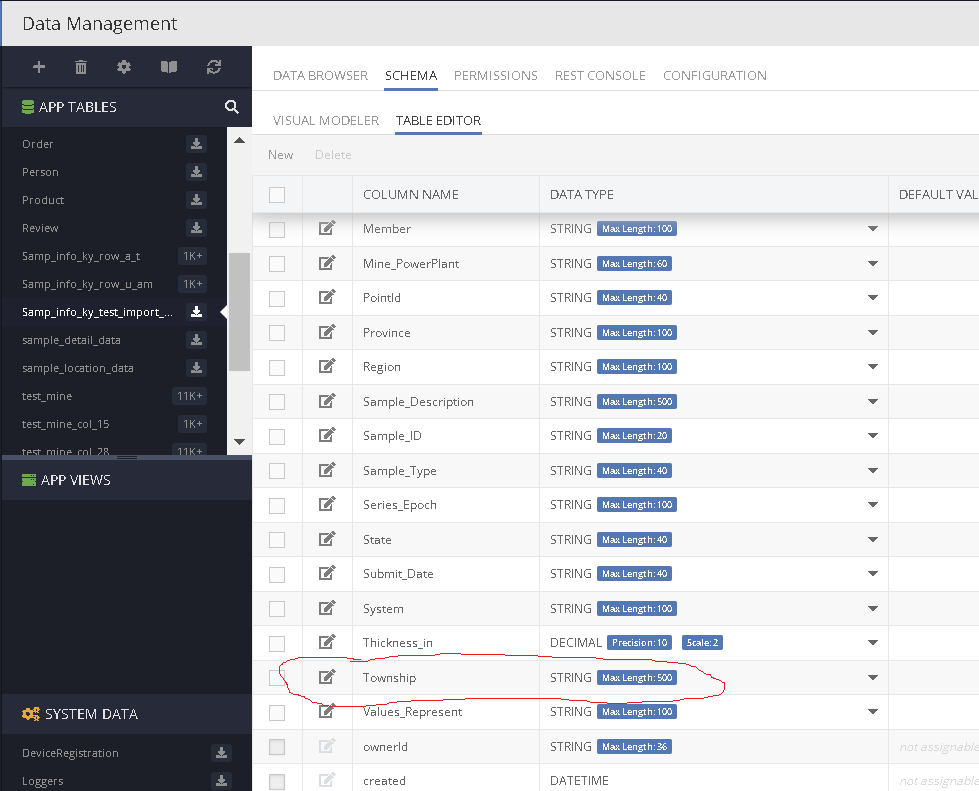
couple of things, I thought it imported all the c9olumns but it seems to be missing a few. it did not import columns Range, Section, Quarters, and Tract
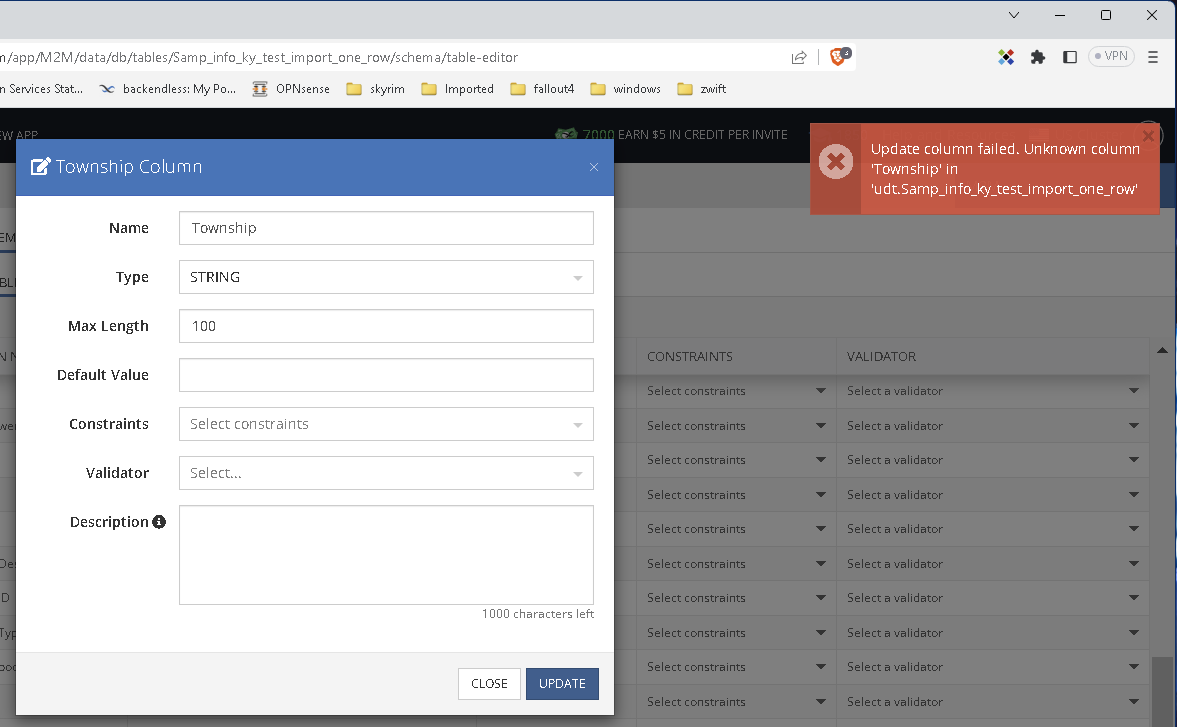
also during import, you have no way to set the sting lengths. So I thought i’d use the table that imported (with 0 rows) and i’d set the string lengths there and import the table again so see if that worked. while I was doing that (this is when I noticed missing columns ) and I tried to edit column Township (change the string from 500 to 100 ) when i clicked update I got this error.
but you can clearly see the column
so I’m not sure what to make of that.
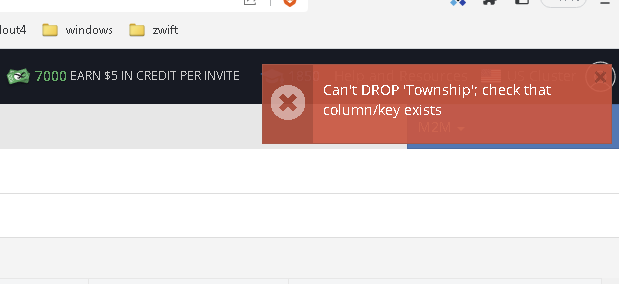
EDIT: also when I tried to delete the Township column i get this error.
Hi @hharrington
Unfortunately, you will need to completely delete this table because there was an error during the import process while creating the “Township” column. As a result, the data indicating that the column should exist was saved, but the column itself does not exist. We will address this issue in upcoming releases to prevent such occurrences.
The initial unsuccessful import occurs because STRING columns are declared in the database as varchar(500) by default, where each character occupies 4 bytes, resulting in each column occupying 2000 bytes. In your file, you have 37 columns. The first 32 columns are imported successfully, but the 33rd column (the “Township”) causes an error due to exceeding the maximum allowed string size (65535 bytes), and the import process is interrupted. Additionally, the “Range,” “Section,” “Quarters,” and “Tract” columns are left out. This all happens during the table creation stage.
Workarounds at the moment. To ensure a successful import, you can:
a) In the console, after parsing the CSV file, change the column types wherever possible (to have fewer remaining STRING columns) and then click “Finalize Import.”
b) Alternatively, you can initially edit your CSV file in an editor by adding the value ({""dataSize"":250}) after the name of each column.
It should look something like this:
Sample_ID({""dataSize"":250}), State({""dataSize"":250}), County({""dataSize"":250})..., and so on. Instead of 250, you can use the size that you currently set as the Max Length.
Apologies once again for the inconvenience.
Regards,
Viktor
Hey,
thanks for getting back to me. I see the issue, I did not realize each char in a string type took 4 bytes, so my math was off by 4x.
I kind of figured the table was corrupt so I did delete it.
I am not able to significantly reduce the number of strings in my table but I tried out your plan b and that worked.
H
how would I do
County({““dataSize””:250})
for a decimal with precision 10, scale 2 ?
Hi @hharrington
If you want to specify a DECIMAL type with a precision of 10 and a scale of 2, it would be as follows:
...,"County({""type"":""DECIMAL"",""dataSize"":10,""decimalScale"":2})",...
Please note that external quotation marks are necessary to describe this column in this case since multiple parameters are listed separately by commas. The external quotation marks ensure that the parser understands that these commas separate the parameters of a single column, not the columns themselves.
Regards,
Viktor