My Backendless application will be receiving a data object from an external API that looks like this:
I break down the array and host it in 3 separate tables, one for parents, one for students, one for lessons. Each row of the parent table has a relation of 1:N with students, and each row of the student table has a relation of 1:N with lessons.
I would like to minimize the number of API calls and the processing time in Backendless.
My question is: what is the best way to structure this in Backendless Codeless?
Option 1:
- Create a Timer that calls the parent array from the API and create/update rows in the parent table.
- Create 2 more timers for the second and third tables, and one to set the relations.
Option 2:
- Create a timer with one API call, store the students and lessons in the parent table as JSON objects
- Then take the JSON object and create rows in the student and lesson tables.
Is this the right way to use the JSON schema in Backendless tables? Is there a best practice I should follow?
In my opinion, the best way to determine the data structure in Backendless (and this applies not only to Backendless, but to any persistent storage), is to start from the user experience and understand how the data will be used. What is the pattern of retrieval and updates from the client-side perspective? That should be the driving factor for your data model design. Seeing how the data is structured in the external source is good, but it should never be the primary factor (again, this is IMHO). I know I am not giving you a straight answer - I am simply trying to open up the perspective.
Regards,
Mark
Thanks @mark-piller, I believe I can use JSON here as the pattern of retrieval and updates and user experience allow it.
My logic currently works well and I am able to transform the data to my liking and add it to my datatable. This in itself is exciting for me as I am parsing a complex data object.
However, despite the fact that I have installed the Enhanced Script/Code Execution Time (20 sec), my task execution is aborted due to timeout 30022.033ms.
It is able to add 210 objects out of the 366, but in the future I expect to have up to 5000 objects.
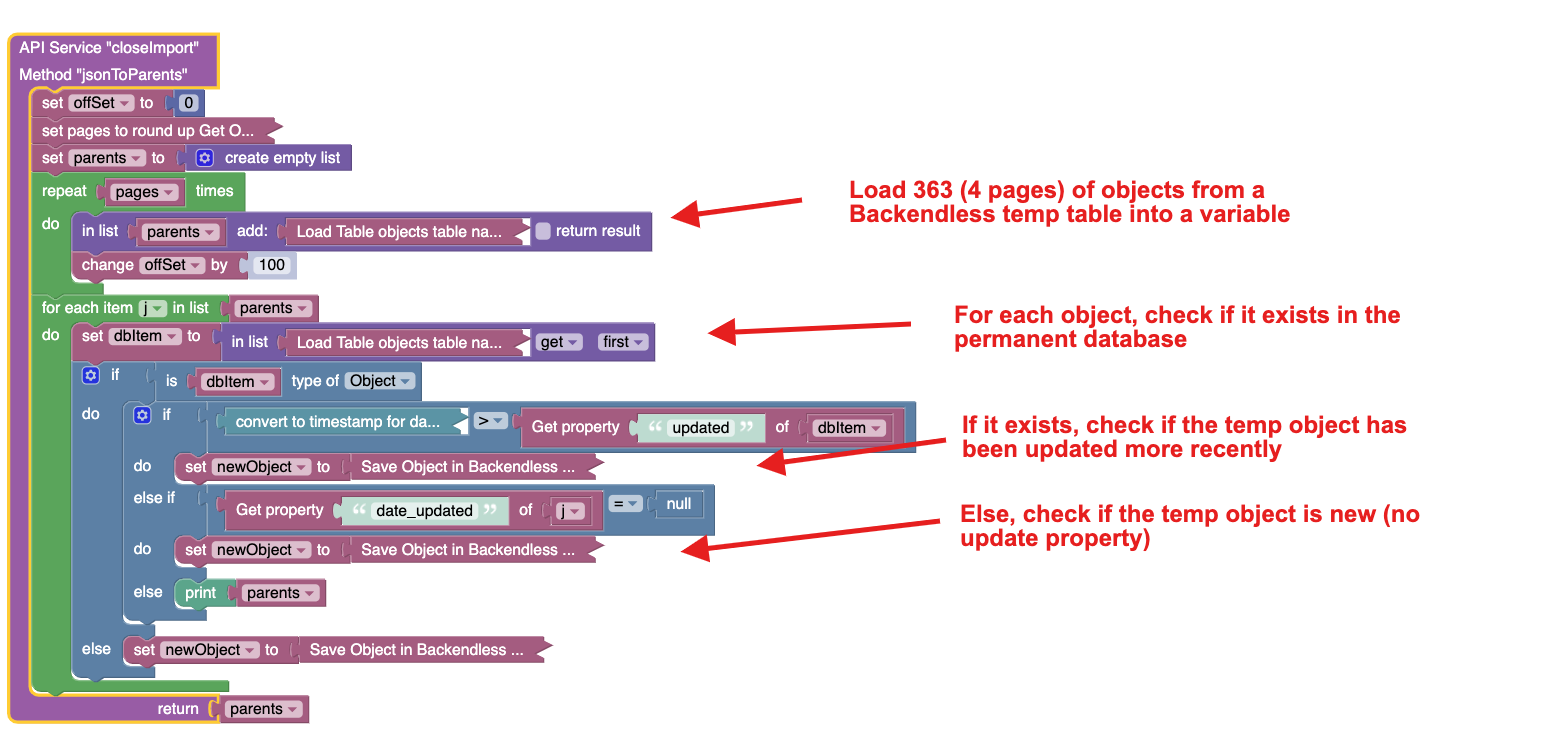
Here’s the jist of my logic:
- I pull 4 pages of 100 data objects from an external API ( enrolledParents custom function)
- For each object, I check if it is already in the DB (importParents* API service)
- If so and the timestamp is older than the external data, I update it
- If not I add it.
I guess it is a best practice to reduce execution time of each task. How would you think about doing that?
eg. Add step 1 as JSON objects to a separate table and create a Timer to complete step 2-4?
My App ID is 4A47197B-AE30-FA84-FF56-0071F4010900.
No need for detailed feedback, buy any insights on avoiding task timeout would be appreciated.
Update, I broke out step 1 and 2-4, so I first bring everything from the api into a temp table ( testLoad* to jsonClose), this works fine.
Then using a separate method (which I will turn into a timer) I do steps 2 to 4 but I am still getting timeouts ( jsonToParents* to parents). I find it strange that it is timing out.
Here’s what this second method does:
This is mission critical for me, what approach should I take? Is there a way that I can minimize the execution time?
Is there I way I can only take 100 objects from the temp table in each run, so it does not time out?
tip: if you use the print block and log the time for each step, you will get a better idea of where most of the time is being spent in your business logic.
By looking at the timestamps in the real-time logging window, I was able to finentune the logic, splitting it where necessary to balance execution time vs number of API calls.
1 Like