App id A29CAF7F-2332-20F3-FFE4-19FEA411AE00
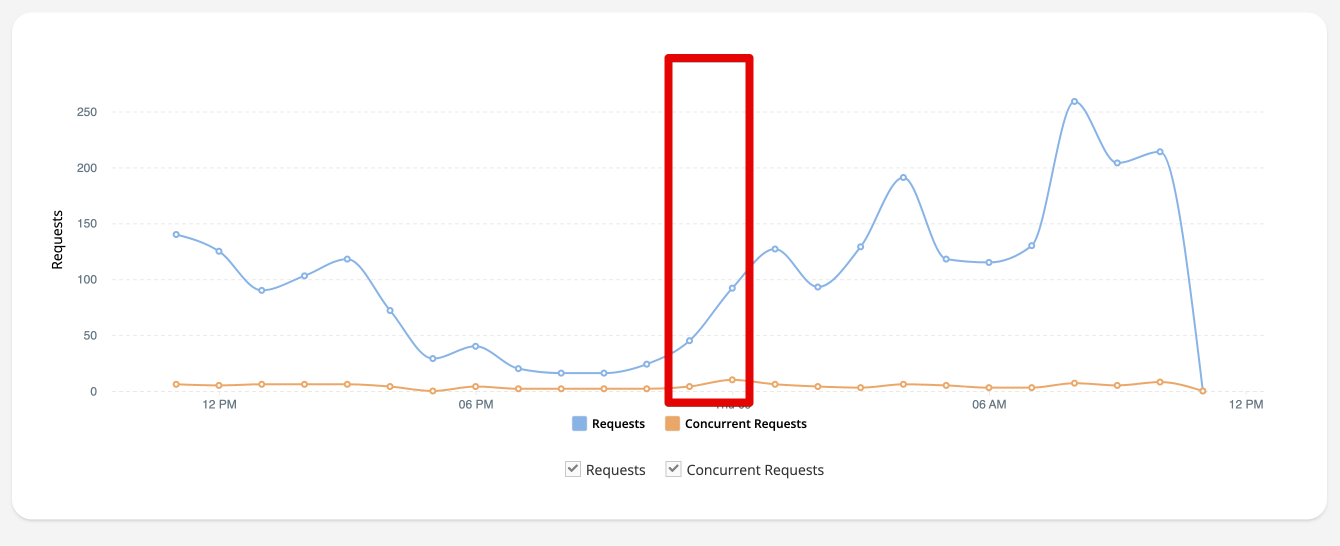
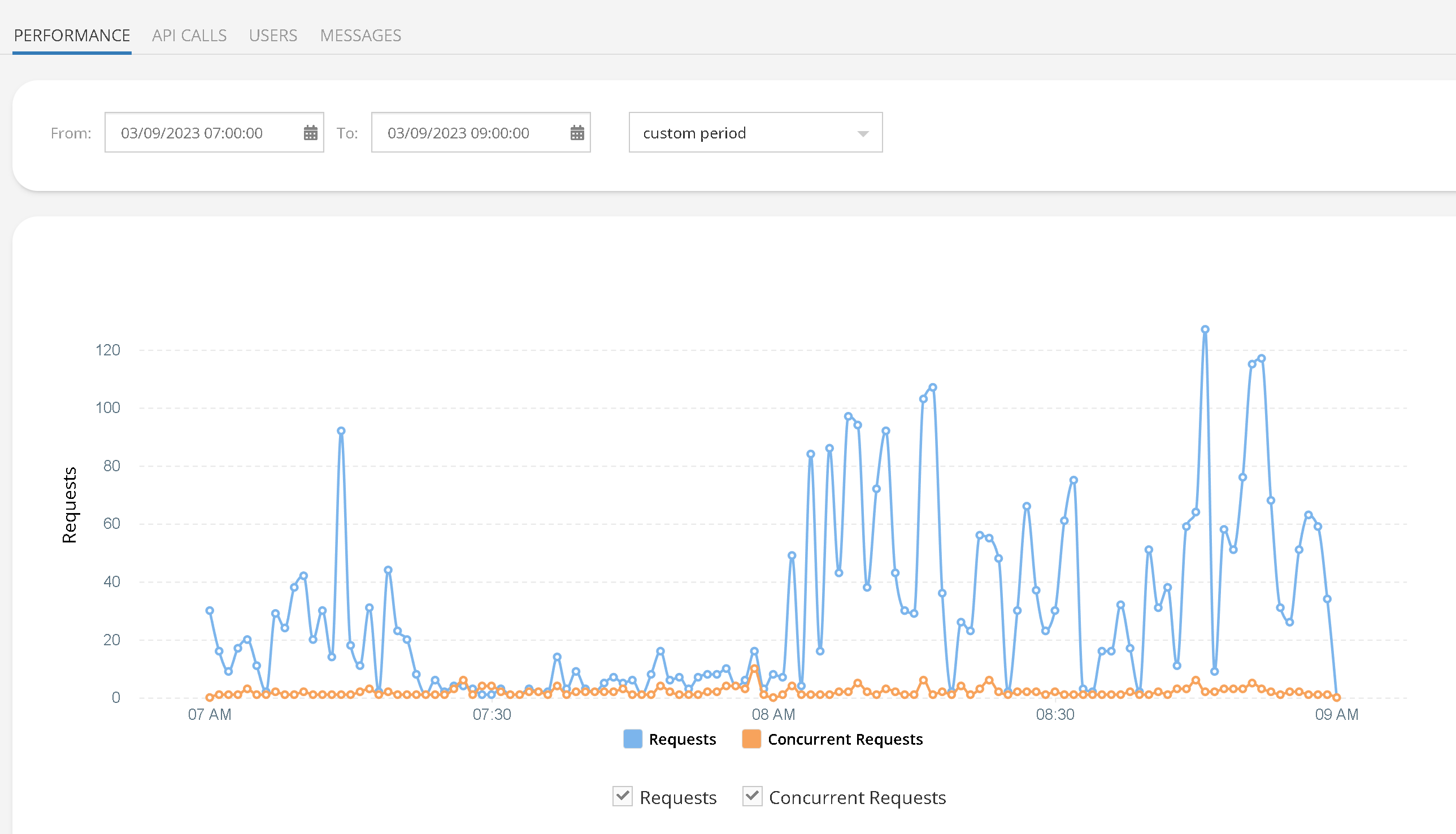
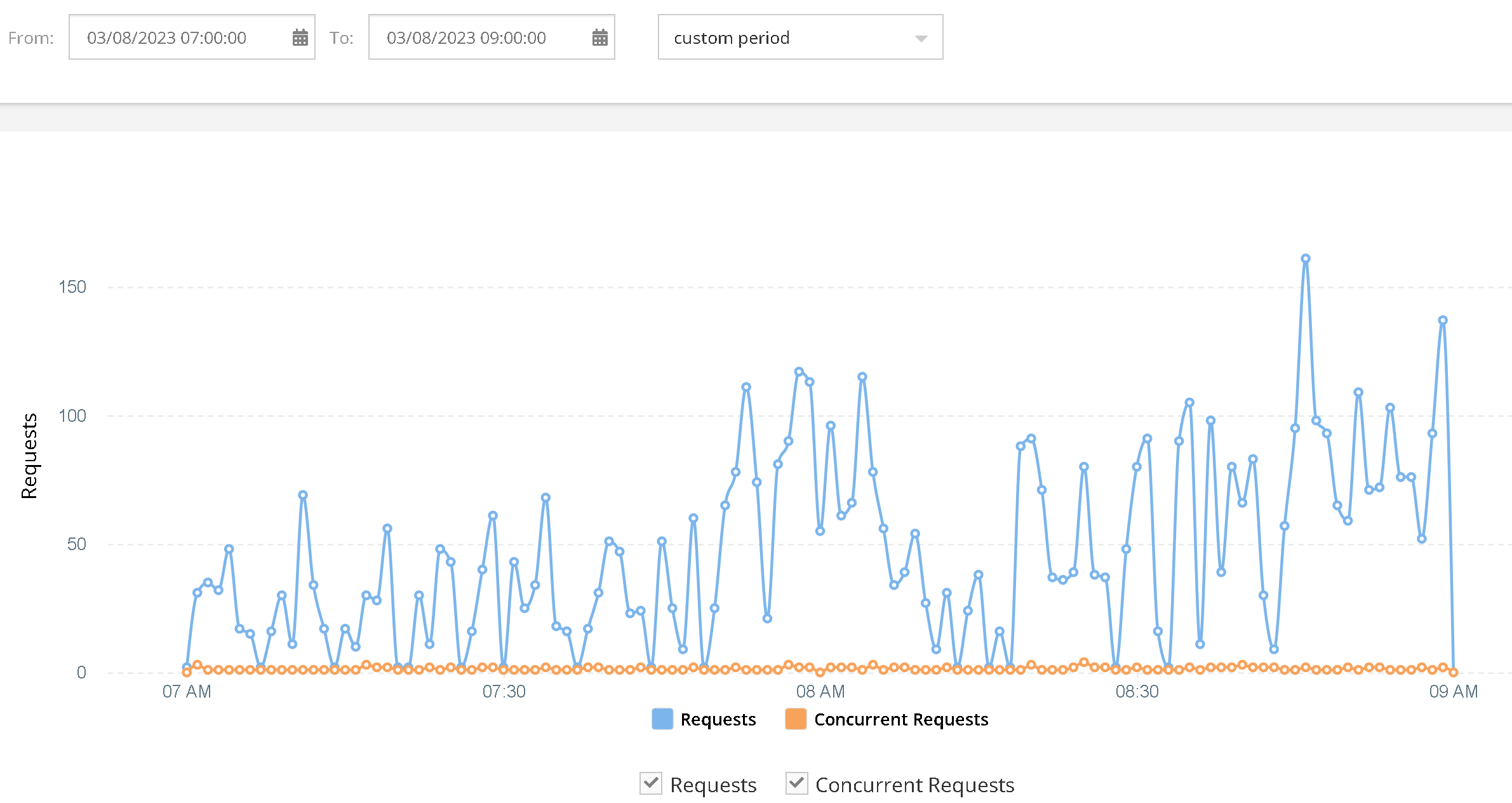
Completely down since 30 min ago.
Files does not load when trying to view them in console.
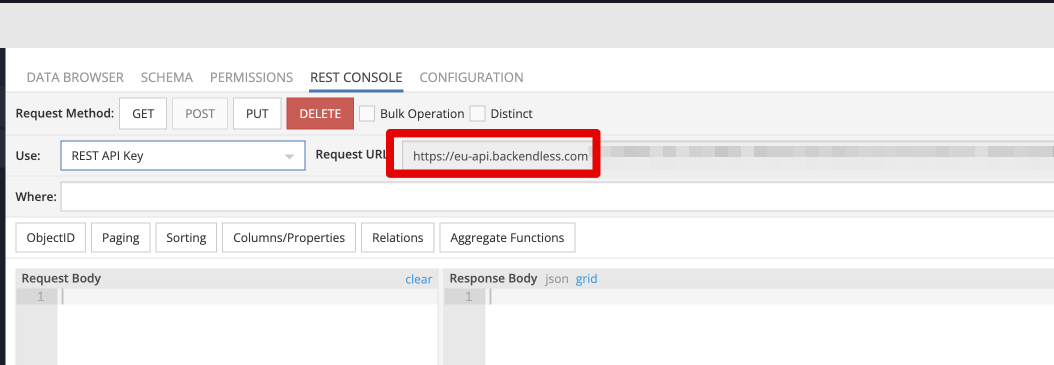
Http shows error: {“code”:6007,“message”:“The specified resource was not found”,“errorData”:{}}
No changes has been done from our side.
Are you looking for help?
This is a support forum for reporting issues related to Backendless services. Please note that due to our support policy we cannot provide you help with debugging your code, consulting in regards to any language or third-party library usage. For this kind of questions we recommend using more appropriate forums like Stack Overflow.
In order to suggest you a quality solution, we shall usually ask you to provide the details mentioned below first. Including them into your topic right away helps us to start investigating your issue much faster.
In case you have a suggestion or an idea, the details below are not always required, though still any additional background is welcome.
Backendless Version (3.x / 6.x, Online / Managed / Pro )
Client SDK (REST / Android / Objective-C / Swift / JS )
Application ID
Expected Behavior
Please describe the expected behavior of the issue, starting from the first action.
Actual Behavior
Please provide a description of what actually happens, working from the same starting point.
Be descriptive: “it doesn’t work” does not describe what the behavior actually is – instead, say “the request returns a 400 error with message XXX”. Copy and paste your logs, and include any URLs.
Reproducible Test Case
Please provide a simple code that could be run in a new clean app and reproduce the issue.
If the issue is more complex or requires configuration, please provide a link to a project on Github that reproduces the issue.